Plan
In this first part of the series, the plan is to create a bare-minimum skeleton blog. This iteration will have a home page with a list of all existing blog posts and, of course, the blog posts themselves. Additionally, I want it to be hosted somewhere, so it is accessible as soon as possible. I want to share it with some close friends, even in these early stages. In my mind, this creates some sort of ‘contract’ to keep the series going.
I intend to host it via GitHub Pages. At work, we use the GitLab equivalent, so it should be fairly easy to just point it to a public/ folder and see the content appear in a browser.
But one thing after the other, we don’t even have any content yet, let alone have Hugo installed.
Installation
Hugo is open-source, written in Go and hosted on GitHub - gohugoio/hugo. It is available in two editions: standard and extended. The extended edition has some advanced features, such as processing WebP images and transpiling from Sass to CSS. Nothing we cannot live without, so standard edition it is. Or is it?
While it is possible to just download the binary for our system, unzip it and run it, I use Homebrew for installing small tools. Homebrew only provides the extended version as a formula, so I will use that instead. But unless we use the above-mentioned features, everything should also work with the standard version.
Tangent: static vs dynamic linking
Go binaries are usually statically linked. What this means is that everything is included; there are no library dependencies that must be available on your system.
If you want to determine if a binary is statically or dynamically linked, on Linux you can use the ldd command, which will either print all required dependencies or tell you that it is not a dynamic executable.
Running ldd on the standard hugo binary, we see that it is statically linked.
$ ldd ./hugo
not a dynamic executable
Running it on the extended hugo binary, ldd indicates that it requires some libraries and where they have been found.
$ ldd ./hugo
linux-vdso.so.1 (0x00007ffef61af000)
libresolv.so.2 => /lib/x86_64-linux-gnu/libresolv.so.2 (0x00007ffba8694000)
libpthread.so.0 => /lib/x86_64-linux-gnu/libpthread.so.0 (0x00007ffba868f000)
libstdc++.so.6 => /lib/x86_64-linux-gnu/libstdc++.so.6 (0x00007ffba8463000)
libm.so.6 => /lib/x86_64-linux-gnu/libm.so.6 (0x00007ffba837c000)
libdl.so.2 => /lib/x86_64-linux-gnu/libdl.so.2 (0x00007ffba8377000)
libgcc_s.so.1 => /lib/x86_64-linux-gnu/libgcc_s.so.1 (0x00007ffba8355000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007ffba812c000)
/lib64/ld-linux-x86-64.so.2 (0x00007ffba86c0000)
Creating the blog
With Hugo now installed, the Hugo Quick start tells us to create a new site with hugo new site blog.
$ hugo new site blog
Congratulations! Your new Hugo site was created in /home/me/work/blog.
Just a few more steps...
1. Change the current directory to /home/me/work/blog.
2. Create or install a theme:
- Create a new theme with the command "hugo new theme <THEMENAME>"
- Or, install a theme from https://themes.gohugo.io/
3. Edit hugo.toml, setting the "theme" property to the theme name.
4. Create new content with the command "hugo new content <SECTIONNAME>/<FILENAME>.<FORMAT>".
5. Start the embedded web server with the command "hugo server --buildDrafts".
See documentation at https://gohugo.io/.
This creates a basic folder structure that Hugo expects.
$ tree blog
blog
├── archetypes
│ └── default.md
├── assets
├── content
├── data
├── hugo.toml
├── i18n
├── layouts
├── static
└── themes
8 directories, 2 files
Only two files were generated, archetypes/default.md and hugo.toml. Archetypes are templates that are filled whenever we use Hugo to create new content. The hugo.toml contains our site configuration, such as the title, base URL and language code.
And this is the point where we deviate from the norm. Let’s skip all the next steps Hugo told us to perform and immediately build and serve the site, all without any theme or content.
$ cd blog
$ hugo
Start building sites …
hugo v0.132.1+extended linux/amd64 BuildDate=2024-08-13T10:10:10Z VendorInfo=brew
WARN found no layout file for "html" for kind "home": You should create a template file which matches Hugo Layouts Lookup Rules for this combination.
WARN found no layout file for "html" for kind "taxonomy": You should create a template file which matches Hugo Layouts Lookup Rules for this combination.
| EN
-------------------+-----
Pages | 4
Paginator pages | 0
Non-page files | 0
Static files | 0
Processed images | 0
Aliases | 0
Cleaned | 0
Total in 5 ms
$ tree public
public
├── categories
│ └── index.xml
├── index.xml
├── sitemap.xml
└── tags
└── index.xml
Interestingly, Hugo did not really complain about our lack of theme and content and happily generated some files in the public folder.
Warnings are not errors, so for now, I won’t dwell on them too long.
To host the site, all we have to do is serve this public folder via a web server, such as Apache, nginx or a simple python3 -m http.server.
Don’t do the last one in production, though.
An easier way to serve the site during development is using the integrated Hugo server.
Running hugo server will build the site as normal and simultaneously serve it on port 1313 by default.
$ hugo server
Watching for changes in /home/me/work/blog/{archetypes,assets,content,data,i18n,layouts,static}
Watching for config changes in /home/me/work/blog/hugo.toml
Start building sites …
hugo v0.132.1+extended linux/amd64 BuildDate=2024-08-13T10:10:10Z VendorInfo=brew
WARN found no layout file for "html" for kind "home": You should create a template file which matches Hugo Layouts Lookup Rules for this combination.
WARN found no layout file for "html" for kind "taxonomy": You should create a template file which matches Hugo Layouts Lookup Rules for this combination.
| EN
-------------------+-----
Pages | 4
Paginator pages | 0
Non-page files | 0
Static files | 0
Processed images | 0
Aliases | 0
Cleaned | 0
Built in 3 ms
Environment: "development"
Serving pages from disk
Running in Fast Render Mode. For full rebuilds on change: hugo server --disableFastRender
Web Server is available at http://localhost:1313/ (bind address 127.0.0.1)
Press Ctrl+C to stop
As stated above, the Hugo server automatically watches the folders and configuration files for changes and automatically rebuilds the site when anything changes. It will also automatically inject a live-reload JavaScript snippet, so the browser automatically refreshes on any change.
Enough explaining. Let’s see how our site looks!

Fair enough, I expected nothing more since we haven’t really added any content yet. Now, I purposefully ignored the warnings Hugo printed out, but I guess it’s time to look at them now. The astute reader among you may already have figured out a potential issue.
WARN found no layout file for “html” for kind “home”: You should create a template file which matches Hugo Layouts Lookup Rules for this combination.
Without even knowing what a ’layout’ is, the name ‘home’ seems important and may be the actual home page of the blog. Let’s take a look at the official Template lookup order documentation.
Scrolling down to some examples, the documentation states that the ‘Home page’ can be found at many paths: 12 in total. These are ranked in descending search order, meaning Hugo goes through this list from 1 to 12 and takes the first file it finds. First come, first served, so to speak.
Since we have no files whatsoever, we have plenty of options to choose from.
For me, number 4 makes the most sense: layouts/index.html.
So let’s create a super basic layouts/index.html:
<html>
<head>
<title>Blog</title>
</head>
<body>
<p>This is my blog</p>
</body>
</html>
Refresh the browser.

It works!
Templating
But for just a single HTML file, we wouldn’t really need Hugo now, would we?
No, the cool thing about Hugo is templating.
In other words, we can ‘program’ these layouts to alter them during build time.
The Introduction to templating documentation is a great read, especially about context ..
Let’s template our home layout to dynamically include the page title, as shown in the introduction documentation:
.. snip ..
<title>{{ .Title }}</title>
.. snip ..
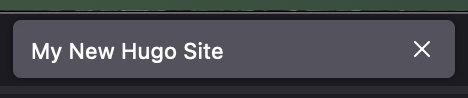
This seems to work out of the box. But where is this title defined, and can we change it? The answer lies only a short ‘grep’ invocation away:
$ grep -r 'Hugo Site'
./public/index.html: <title>My New Hugo Site</title>
./public/index.xml: <title>My New Hugo Site</title>
./public/index.xml: <description>Recent content on My New Hugo Site</description>
./public/tags/index.xml: <title>Tags on My New Hugo Site</title>
./public/tags/index.xml: <description>Recent content in Tags on My New Hugo Site</description>
./public/categories/index.xml: <title>Categories on My New Hugo Site</title>
./public/categories/index.xml: <description>Recent content in Categories on My New Hugo Site</description>
./hugo.toml:title = 'My New Hugo Site'
Ignoring the public directories, since they are effectively the compilation output of Hugo, we remain with a single file: hugo.toml in the current folder.
The hugo.toml file is a site-wide configuration file that contains all sort of settings.
The Configure Hugo documentation page contains a list of all settings that can be configured.
If we open the file, we can see that the site title is set to what we saw: ‘My New Hugo Site’. Time to change it.
baseURL = 'https://example.org/'
languageCode = 'en-us'
title = 'A Binary Blog'
Again, a browser refresh later, and we can see that the HTML title has been changed.
Since this will be a blog, we will have many single posts. For the first iteration, I want the home page to have a list of all available posts, including a link to them that a visitor can click on.
But before we can even generate a list, we have to have some posts. Since I’m dogfooding this blog, I already have some posts, namely the introduction and this one. But for you, dear reader, I’m just going to create two dummy posts on which we can implement this new feature.
Let’s create them in the content/posts folder. content/posts/000-zero.md and content/posts/001-one.md:
+++
title = 'Post Zero'
+++
This is the content of post zero.
If you have never written Markdown for any static site generator, the content between the ‘+++’ lines is called the Front Matter. It’s here to define metadata for the content, such as the post title, its creation date or anything custom.
Having created these two files, if you look back at the console, Hugo is still running and reports a new warning message we know too well.
WARN found no layout file for “html” for kind “page”: You should create a template file which matches Hugo Layouts Lookup Rules for this combination.
Taking a look at the Template lookup order again, we can see that one path for the ‘Single page in “posts” section’ is layouts/posts/single.html.
Time to create a new layout:
<html>
<head>
<title>{{ .Title }}</title>
</head>
<body>
<h1>{{ .Title }}</h1>
<br>
{{ .Content }}
</body>
</html>
The layout is very similar to the home one. For the page body, I have included the title as a heading, a forced new line and then the rest of the content. The Content method returns the rendered content of the page.
During its build step, Hugo takes a markdown file, renders it as HTML content, finds the relevant template, and uses that to build the final HTML output. If we were to have hard-coded the template body, all our posts would have the same content.
With this layout in place, the warning has vanished.
If we look inside the public folder, we can see that Hugo has rendered our dummy posts into HTML files.
Since we know the structure of our posts, we can visit it directly in the browser.
Let’s go to http://localhost:1313/posts/000-zero and see what we can find.

It’s our post!
Including the content we have written inside the markdown file, all rendered as HTML.
Visiting http://localhost:1313/posts/001-one yields the same layout, but with the content from content/posts/001-one.md.
With some dummy posts in place, what I want is a list of all posts on the home page as a link. Welcome to the ‘range’ operator.
To iterate over all possible posts, we first need to know what posts there are.
The Site - Pages method returns a collection of all pages in our Hugo site, and with the ‘range’ operator, we can iterate over each one.
Let’s edit layouts/index.html:
.. snip ..
<body>
<p>This is my blog</p>
<ul>
{{ range .Site.Pages }}
<li><a href="{{ .Path }}">{{ .LinkTitle }}</a></li>
{{ end }}
</ul>
</body>
.. snip ..
First, we create an unordered list ul, then iterate over all site pages.
Within the ‘range’ and ’end’ directives, our context . is now the page object itself.
We can access its Path and LinkTitle to create a list item li and a href that points to the URL of the post.
Finally, close the unordered list, and we should have a list of all posts on our home page.

That’s… certainly interesting.
It seems we have a lot more pages than we initially thought.
Reading the documentation of the Pages method again more closely, we can see why these additional pages are included.
This method returns all page kinds in the current language. That includes the home page, section pages, taxonomy pages, term pages, and regular pages.
In most cases you should use the RegularPages method instead.
The root ‘A Binary Blog’ page is our home page.
The ‘Categories’ and ‘Tags’ pages are so-called ‘Taxonomy’ pages, essentially a grouping of content.
The ‘Posts’ page is a ‘Section’ page, which is a content directory.
For now, these additional pages are not interesting to us, so let’s follow the documentation and use RegularPages instead.
.. snip ..
<ul>
{{ range .Site.RegularPages }}
.. snip ..
And with that, we have a super basic overview of all the available posts:

Styling
With a super basic layout structure, it’s now time to style it to make it pretty, right? Not quite yet, I’m afraid.
A big motivation factor for me is that any small change is visible as soon as possible. For this reason, I will postpone the styling in favor of the following:
Deployment
Because Hugo is a static site generator, hosting the output is as simple as pointing a web server to the public folder.
I won’t go into too much detail about it here, since the Hugo documentation Host on GitHub Pages is excellent.
One small hiccup I ran into was configuring the correct DNS records.
When I was reading the Managing a custom domain for your GitHub Pages site documentation, I totally glossed over the fact that configuring an apex domain is different from a subdomain.
So what I did was diligently create all the required A and AAAA records, configure the custom domain in the GitHub repository settings, and was promptly confused on why GitHub told me the DNS records were wrong.
After changing the 8 separate records to a single CNAME record, I waited until the records were propagated and the DNS check succeeded, enforced HTTPS and voilà, here we are.
Afterword
With this, I now have the most basic blog setup ever. It isn’t and doesn’t look like much, but it’s basic enough; I understand every facet of it, and it’s automatically deployed publicly. The walking skeleton is complete; time to style it up.